Distributed Book Scraper: Arquitectura Serverless AWS
Sistema de scraping escalable, desacoplado y asíncrono utilizando AWS SAM, TypeScript y Go.
TL;DR - Executive Summary
Diseñé e implementé una infraestructura en la nube orientada a eventos para la extracción e indexación de libros. El proyecto utiliza un patrón de Worker asíncrono para sortear los límites de timeout, colas de mensajes (SQS) para el manejo de carga, y políticas IAM de menor privilegio configuradas como Infraestructura como Código (IaC).
Arquitectura Orientada a Eventos (Event-Driven Topology)
Complete event-driven flow from ingestion to storage
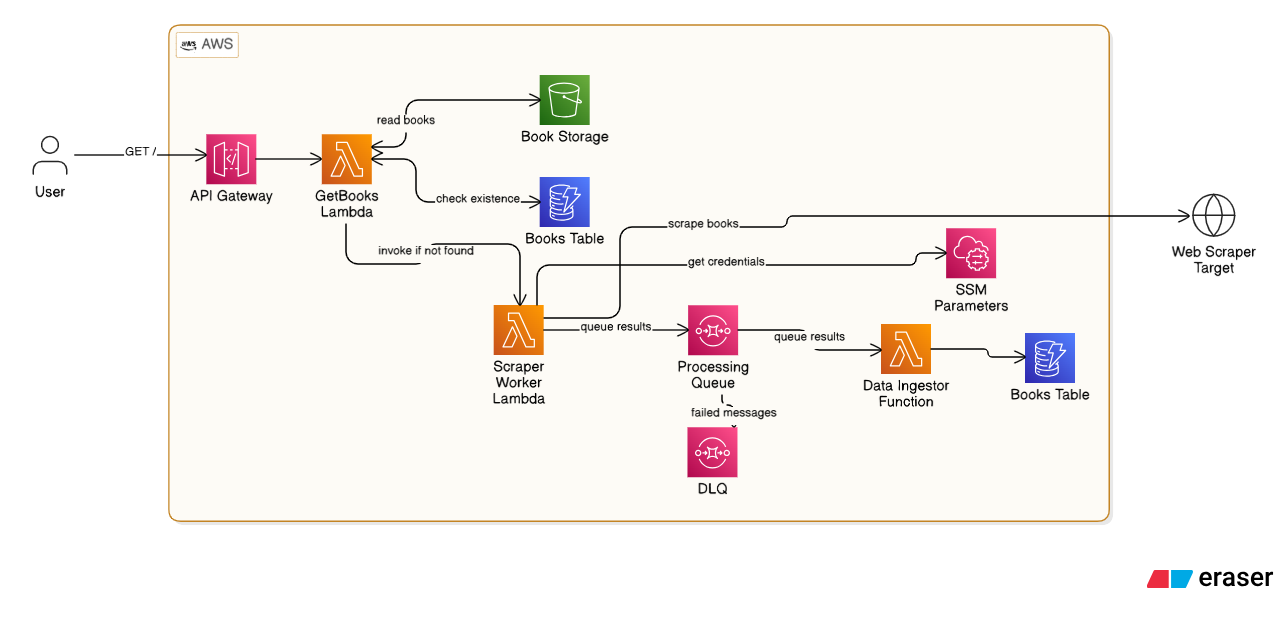
Patrones de Diseño Backend
Desacoplamiento con Workers
GetBooksFunction delega el trabajo pesado a ScraperWorkerFunction para no bloquear API Gateway. Este patrón asegura APIs responsivas mientras el procesamiento continúa asincronamente en segundo plano.
Resiliencia y Colas (SQS + DLQ)
Implementa MaximumBatchingWindowInSeconds: 30 y Dead Letter Queue (DLQ) para tolerancia a fallos. Los mensajes fallidos se capturan y pueden ser reproducidos o analizados para depuración sin perder datos.
Arquitectura Multi-Lenguaje
Combinación estratégica de TypeScript y Go, cada lenguaje optimizado para su dominio específico. TypeScript maneja la orquestación de API y la lógica empresarial, mientras que Go potencia el análisis ultra-rápido de Sitemaps y las operaciones de scraping intensivas en CPU.
Evasión Avanzada Anti-Scraping (Integración Bright Data)
Para evitar el rate-limiting y el baneo inmediato de IPs de AWS Lambda por parte del e-commerce, integré una solución de rotación dinámica de IPs residenciales geolocalizadas a nivel local utilizando la red de proxies de Bright Data dentro de cada ejecución de Playwright, simulando tráfico de usuarios legítimos para garantizar una tasa de éxito de extracción casi perfecta.
Infraestructura como Código (IaC)
Resources:
BookScraperQueue:
Type: AWS::SQS::Queue
Properties:
RedrivePolicy:
deadLetterTargetArn: !GetAtt BookScraperDLQ.Arn
maxReceiveCount: 3
MessageRetentionPeriod: 86400
VisibilityTimeout: 300
BookScraperDLQ:
Type: AWS::SQS::Queue
Properties:
MessageRetentionPeriod: 1209600
ScraperLambda:
Type: AWS::Serverless::Function
Properties:
Handler: dist/index.handler
Runtime: nodejs18.x
Events:
SQSEvent:
Type: SQS
Properties:
Queue: !GetAtt BookScraperQueue.Arn
BatchSize: 10
MaximumBatchingWindowInSeconds: 30Fragmento YAML mostrando la definición de cola SQS con RedrivePolicy apuntando a DLQ. Sin clics manuales en la Consola AWS—todo es código y versionado.
Características Técnicas Clave
Estrategia de caché basada en TTL de DynamoDB (campo purge_at) para gestión automática del ciclo de vida de datos
Integración CI/CD con despliegues basados en entornos (dev, qa, prod vía SAM)
Gestión segura de secretos usando AWS SSM Parameter Store para credenciales de scraping
Interesado en este proyecto?
Este proyecto demuestra arquitectura serverless escalable, patrones event-driven avanzados y soluciones prácticas para web scraping distribuido.